آموزش نرمافزار SPSS (جلسه شانزدهم)
– رگرسیون چند گانه در SPSS:
رگرسیون چندگانه به همبستگی دو متغیر توسعه میبخشد. نتیجه رگرسیون معادلهای است که بهترین پیشگوئی یک متغیر وابسته را از روی چند متغیر مستقل نشان میدهد. رگرسیون چندگانه زمانی که متغیرهای مستقل با یکدیگر و با متغیر وابسته مرتبط اند استفاده میشود. متغیرهای مستقل میتوانند پیوسته یا ردهای باشد و اکثر اوقات متغیر وابسته پیوسته است. اگر متغیر وابسته پیوسته نباشد، تحلیل تابع ممیزی و یا رگرسیون لجستیک مناسب است.
– اهداف رگرسیون چندگانه:
1- یافتن بهترین معادله پیشگوئی برای مجموعهای از متغیرها
2- کنترل عامل های مزاحم برای بررسی سهم یک متغیر یا مجموعهای از متغیرها
3- یافتن روابط ساختاری و ارائه توضیحاتی برای روابط چند متغیره پیچیده
– فرضیاتی که برای انجام تحلیل رگرسیونی باید برقرار باشند به صورت زیر است:
1- نسبت مشاهدات متغیرهای مستقل برای رگرسیون استاندارد یا مرتبهای باید بیست برابر تعداد متغیرهای مستقل باشد و برای رگرسیون گامبهگام مشاهدات بیشتری لازم است.
2- نقاط پرت و مشاهدات دور افتاده بر مدل رگرسیون اثر میگذارند و باید به وسیله جدول فراوانی پیدا و حذف یا اصلاح شوند.
3- چند هم خطی بین متغیرهای مستقل که همان همبستگی شدید میان متغیرهای مستقل است و تکینی زمانی رخ میدهد که همبستگی کاملی بین متغیرهای مستقل وجود دارد.
4- نرمال بودن، خطی بودن، همگنی واریانسها و استقلال باقیماندهها که با رسم نمودارهای پراکنش باقیماندهها میتوانیم این موارد را بررسی کنیم.
از منوی Analyze به ترتیب گزینههای Regression و …Linear را انتخاب کنید. متغیر وابسته را به قسمت Dependent و متغیرهای مستقل را به قسمت (Independent(s انتقال دهید. از قسمت Method گزینه Enter را انتخاب کنید.
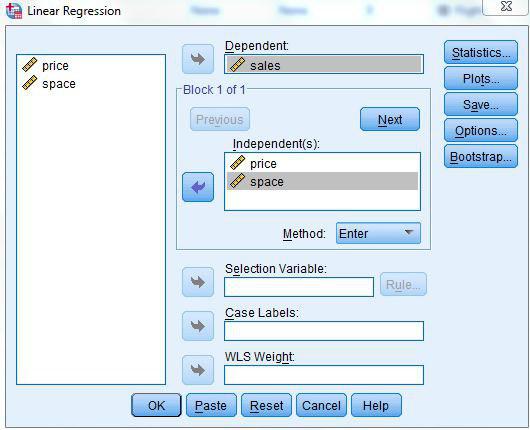
روی دکمه …Statistics کلیک کنید. مطمئن شوید گزینههای Estimates و Model fit انتخاب شده باشند. درقسمت Residuals گزینه Casewise diagnotistics راانتخاب نمایید.

روی دکمه Continue کلیک نمایید. اکنون روی دکمه …plots کلیک نمایید. ازاین کادر ZRESID* (باقیماندههای استاندارد شده) را انتخاب و به قسمت :Y انتقال دهید، سپس ZPRED* (مقادیر پیشبینی استاندارد شده) را انتخاب و به قسمت :X منتقل نمایید، در پایین کادر گزینه Normal probability plot را انتخاب و سپس روی Continue کلیک کنید.

روی دکمه …save کلیک کنید. از قسمت Distance گزینهی Mahalanobis را انتخاب وسپس روی Continue و OK کلیک کنید.

خروجی به صورت زیر خواهد بود:
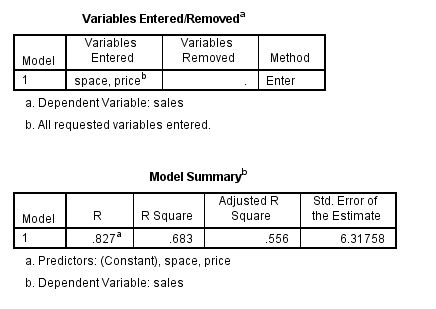
به R ضریب همبستگی چندگانه و به R Square یا به اختصار R2 ضریب تعیین چندگانه گویند. مقادیر بزرگ R همبستگی قوی را نشان میدهد. مقادیر کوچک R2 نشان میدهد که مدل رگرسیونی نمیتواند دادهها را خوب برازش دهد. با استفاده از R2 میتوانیم بهترین مدل برای برازش دادهها را پیدا کنبم. در مدلهایی که متغیرهای زیادی ندارند، مقادیر بزرگ نشان از خوب بودن آن مدل نسبت به دیگر مدلهاست. اما در مدل هایی که متغیرهای زیادی درگیر هستند، تفسیر با استفاده از R2 تعدیل شده یا Adjusted R2 صورت میگیرد.
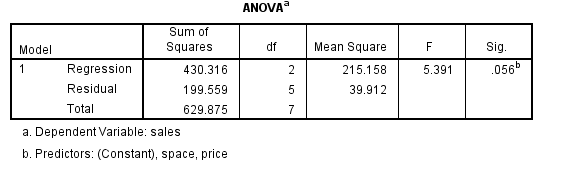
با توجه به جدول فوق، دو متغیر باهم، 85 درصد واریانس متغیر وابسته Sales را بیان میکنند که با توجه به مقدار 34.081=F و یا مقدار معناداری گزارش شده 0.000=.Sig در جدول زیر معنادار است:
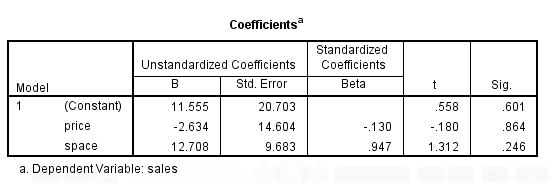
در جدول زیر، معناداری اثرات متغیرهای مستقل آزمون شده است. آماره 3.219=t با توجه به مقدار معناداری مرتبط با آن، یعنی 0/007=.Sig، نشان میدهد که متغیر price بر پیشگویی متغیر وابسه sales اثری معنادار دارد.
چون هیچ نقطهی پرتی وجود نداشت، نمودارهای casewise رسم نشدند. اگر این نمودارها رسم شوند، نقاطی را که بیش از 3 انحراف معیار از میانگین فاصله داشته باشند، نشان میدهند. از روی نمودارهای پراکنش باقیماندهها و مقادیر پیشبینی شده، میتوان مشاهده کرد که هیچ رابطهی مشخصی میان باقیماندهها ومقادیر پیشبینی شده وجود ندارد، که با فرض خطی بودن سازگار است.
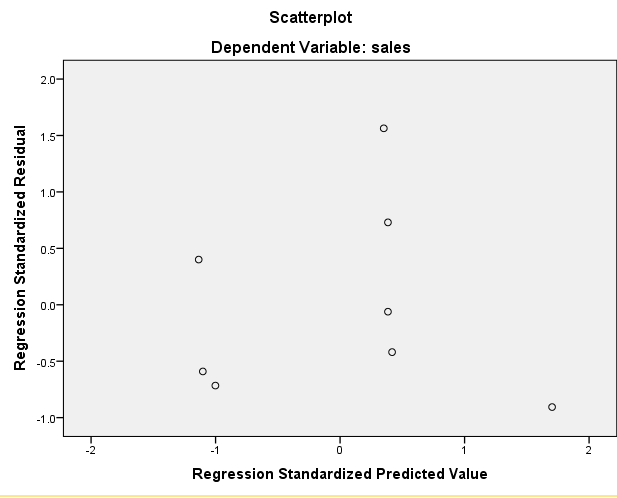
همچنین از روی نمودار Normal p-p plot of Regression Standardized Residual برای متغیر وابسته، میتوان مشاهده کرد که باقیماندهها نسبتا بطور نرمال توزیع شدهاند. چون طبق این نمودار، اگر تمام نقاط روی نیمساز ربع اول باشند، آنگاه دادهها کاملاً از توزیع تبعیت میکنند. با توجه به شکل زیر دادهها تقریبا از توزیع نرمال تبعیت میکنند:


دوره آموزش آماری / کارگاه آموزش مدیریتی / آموزش پایان نامه نویسی / آموزش مقاله نویسی
مطالب مرتبط:
- کارگاه آموزشی نرم افزار SPSS (مقدماتی و پیشرفته )
- آموزش نرم افزار SPSS (جلسه پانزدهم )
- آموزش نرم افزار SPSS (جلسه چهاردهم )
- آموزش نرم افزار SPSS (جلسه سیزدهم )
محصولات
-
 دوره خلاقیت، ایدهیابی و نوآوری حضوری 300,000 تومان
دوره خلاقیت، ایدهیابی و نوآوری حضوری 300,000 تومان - تعمیرات قطعات کامپیوتر (غیر حضوری) 300,000 تومان
- مایعدرمانی و مروری بر اختلالات آب و املاح در سگ و گربه 200,000 تومان
- کارگاه آموزشی ترجمه و ویرایش مقالات ISI 210,000 تومان



